Diagnosis of Spinal Pathology Using Case-Based Reasoning
30/06/2020 Views : 445
I Wayan Supriana
The spine is a flexible structure formed by a number of bones called vertebrae or vertebrae. The human spine consists of 33 vertebrae which are arranged together and have various sizes. The human spine has a role as a supporter of a sturdy body, carrying weight, making the body flexible like bending, and protecting the spinal cord as well as nerves. It can be seen that the spine is a very important part of the human body. This very complex system can experience disorders that cause pain with varying intensities. Pathology is the science and medical discipline that deals with the interconnected anatomical, functional, and clinical causes, mechanisms and manifestations of disease. Examples of pathologies that can occur in the spine are Hernia and Spondylolisthesis disk, both of these pathologies can cause severe pain. Spondylolisthesis is the occurrence of forward displacement of the spine relative to the underlying bone. Disk Hernia is the local displacement of disk material outside the normal limits. Through the case-based reasoning approach (case-based reasoning) pathology diagnosis can be performed on the spine, the technique adopted uses patient data that has been previously stored which can be reused as a reference in classifying new spinal disease data using the algorithm K-Nearest Neighbor (KNN)
How does case-based
reasoning make its reasoning process?
Case-based reasoning
is a reasoning method that uses references to old cases that have a closeness
to a new case and then adopts a solution to be able to solve problems in a new
case. There are 4 stages in the case-based reasoning process:
1. Retrieve, retrieval
of old cases that are similar to new cases
2. Reuse, reuse old
cases that were retrieval as resolutions adopted for new cases
3. Revise, a review and
amendment of the solution if needed for a new case
Retain, the outcome of problem resolution is considered a new case and can be added on a case basis
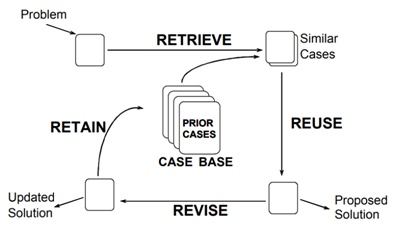
Figure 1. Case-Based Reasoning
Cycle
How does the
K-Nearest Neighbor (KNN) algorithm do the classification?
K-Nearest Neighbor (KNN) algorithm is a method of classifying
data by calculating the distance between new cases and old cases. This
algorithm will classify new data that is not yet known by its class by
selecting the closest number of k data as the prediction of a new class. The
distance calculation formula uses Euclidean Distance, 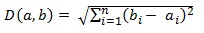 where (d) the distance between
the two cases, (b) new cases, (a) cases that are on a case basis, (n) number of
features in each case, (i) individual features between 1 and n.
where (d) the distance between
the two cases, (b) new cases, (a) cases that are on a case basis, (n) number of
features in each case, (i) individual features between 1 and n.
How is the
application of spinal pathology using case-based reasoning?
Process at the stage
of retrieve
This stage will look
for similarity values between new cases and old cases using the Euclidean
Distance formula that has been combined with the weight value of each feature,
for example:
Table 1. Value of New Case and Old Case Features
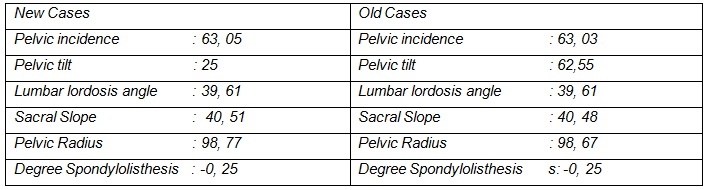
It is necessary to calculate the distance of the new cases above with each old case in the case base. In the example of calculating the distance between new cases and old cases below is the calculation in table 1 of the above cases, with weights determined based on the correlation between the dominant features on the basis of the cases used.
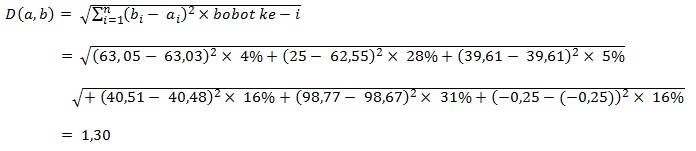
In the example above, the distance between new cases and old cases is 1.30. The calculation above continues to be done for all cases long time after all values have been obtained then it needs to be sorted as many times as the nearest k. In general, the k commonly used is odd, in this case the k value used is 5
Table 2. Results 5 Nearby Data

Process at the reuse
stage
This stage will use
the results of the diagnosis in the previous case to diagnose the new case by
selecting the most dominant class from the closest number of k data. In this
case, it can be seen in Table 2 that from the new data tested, we get the 5
closest data to the most dominant class, DH or Disk Hernia, compared to NO or
normal class.
Process at the revise
stage
At this stage a new
case is revised so that the solution of the new case is not exactly the same as
the old case, the case base will always develop with the respective solution in
the case.
Process at retain
stage
All new data that did
not exist before in the database will be saved again and will be used as a case
base in the future
Program Implementation
Figure 2. Display Input
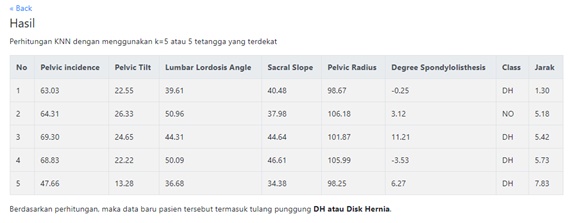
Figure 3. Display Calculation Results
The diagnosis of spinal pathology uses case-based reasoning with the calculation of similarity between new cases and old cases using the KNN algorithm. Based on the system testing of the predetermined testing data, the accuracy of the diagnosis of the system is obtained by 88.17% determining whether a person has spinal pathology or not.
References
E.
C. Pearce, Anatomi & Fisiologi U.Ps. Gramedia Pustaka Utama.
L.
M. Buja and G. R. F. Krueger, Netter's Illustrated Human Pathology Updated
Edition E-book: with Student Consult Access. Elsevier Health Sciences, 2013.
R.
Gunzburg and M. Szpalski, Spondylolysis, Spondylolisthesis, and Degenerative
Spondylolisthesis. Lippincott Williams & Willkins, 2006.
B.
N. W. Weissman, Imaging of Arthritis and Metabolic Bone Disease.
Mosby/Elsevier, 2009.
A.
T. Azar, H. S. Ali, V. E. Balas, T. Olariu, and R. Ciurea, "Boosted
decision trees for vertebral column disease diagnosis," in International
Workshop Soft Computing Applications, 2014, pp. 319-333: Springer.
C.
S. Fatoni, E. Utami, F. W. J. I. J. A. I. Wibowo, and Informatics, "Expert
system for diagnosing diphtheria with k-nearest neighbor method," vol. 1,
no. 2, pp. 45-56, 2018.
M.
Minarni and I. Warman, "Sistem Pakar Identifikasi Penyakit Tanaman Padi
Menggunakan Case-Based Reasoning," in Seminar Nasional Aplikasi Teknologi
Informasi 2017, 2017: Islamic University of Indonesia.
R.
L. De Mantaras et al., "Retrieval, reuse, revision and retention in
case-based reasoning," vol. 20, no. 3, pp. 215-240, 2005.
A.
Aamodt and E. J. A. c. Plaza, "Case-based reasoning: Foundational issues,
methodological variations, and system approaches," vol. 7, no. 1, pp.
39-59, 1994.
E. T. L. J. Y.
A. O. Kusrini, "Algoritma data mining," 2009.