Classification of Indonesian Documents Using the Naïve Bayes Multinomial Classifier Method
29/06/2020 Views : 275
I Made Suwija Putra
The need for information increases with the development of technology, but not all information can be a necessity. [1] The information needed is progressing from general information to specific information. The abundance of information and documents available encourages people to find ways to get the right information and documents in a short time. If the document to be searched is in a small number of documents, the search can be done manually. However, if the number of documents available is very large, the manual search process will consume time and effort. If the search time is too long, the benefits of the information obtained can be reduced. This is because the information that has passed a time is useless or invalid. [2].
Therefore, we need a way to obtain data quickly and precisely. Document classification can help the process of finding a document quickly and precisely. Document classification documents according to the categories contained in the document. [3] If there is a request to search for a document that is known to have a certain category, then the search process is only carried out on documents that have that category, the search is not performed on all documents that are owned so that the search process can be done more quickly.
This study uses the Naïve Bayes Classifier (NBC) method, with the aim of classifying documents by that method. This classification is emphasized for Indonesian documents, while the interrelationships between documents are measured based on probability.
The use of NBC in this application is expected to be able to produce accurate data so that it can be used as further research material, the advantage of NBC compared to other algorithms is in its ability to classify documents with simplicity and computational speed but has high computation, the NBC method also has good performance on the classification of document data that contain both numbers and text. Before the classification stage, documents must be presented as vectors. [4].
An overview of the research that discusses the classification of Indonesian documents using the multinomial Naïve Bayes classifier method can be seen in Figure 1.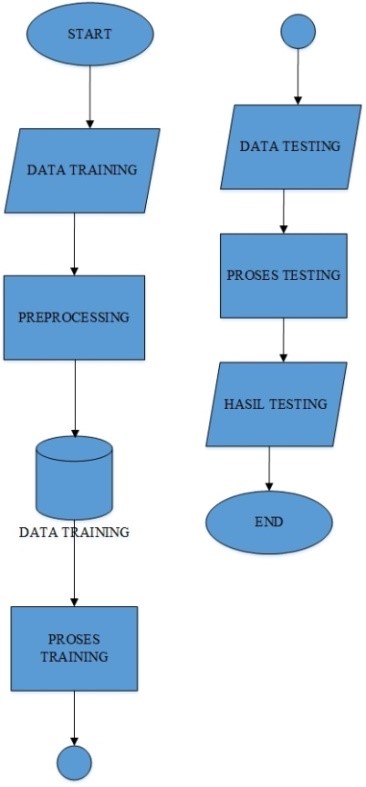
The method used in the classification of this document is the multinomial Naïve Bayes classifier method. The choice of this method is the result of consideration that this method has a high degree of accuracy, is easy to implement, low computing time, and a minimum error rate.
The first workflow of the system is to input training data using titles, categories, and abstracts from journals that are used as training data. After the training data is inputted, a preprocessing of the training data is carried out and the training data is stored in the database. The next step is to carry out the training process which is then followed by testing. The first thing to do when testing is to enter the testing data in the form of a journal-title and abstract to be tested. Then the training process will be carried out and display the results of testing. This classification application is made with the Python programming language using a MySQL database.
Figure 2 above is the result of testing the testing process that has been carried out. The test results will display an abstract of the journal used as testing data. In addition, the results of preprocessing will also be displayed and the most important is the classification result which states the results of the trial in the form of technology with a prediction of 0.78 along with precision, recall, and others. In addition to the above tests, 10 journals with 5 psychological categories and 5 technology journals were also tested. The results of the comparison can be seen in Table 1.
The conclusion that can be drawn in this application is the Naïve Bayes classifier method is quite optimal in its application as a classification algorithm. This can be seen by testing that uses data testing with the technology category and after the testing process, the results are given state that the classification of the technology is a technology which in other words is the expected or appropriate result. In addition, the parameters used are abstracts contained in journals along with the amount of training data used in each type of classification that greatly affects the test results. This study also emphasizes that the need to do preprocessing in journal texts such as the process of removing stop words and stemming, so as to be able to obtain maximum results when testing is done.
Based on 10 tests, obtained accurate or accurate test results 8 times and 2 times incorrect. So, it can be concluded that the accuracy of document classification with the multinomial Naïve Bayes classifier method with 10 tests is 80%.
References
[1] M. Ngafifi, "Kemajuan Teknologi dan Pola Hidup Manusia dalam Perspektif Sosial Budaya," Jurnal Pembangunan Pendidikan : Fondasi dan Aplikasi, vol. 2, p. 33, 2014.
[2] S. Maharsi, "Pengaruh Perkembangan Teknologi Informasi Terhadap Bidang Akuntansi Manajemen," Jurnal Akuntansi & Keuangan vol. 2, pp. 127-137, 2000.
[3] S. A. F. Pratama Dwi Nugraha, Adiwijaya, "Klasifikasi Dokumen Menggunakan Metode K-Nearest Neighbor (KNN) dengan Information Gain " e-Proceeding of Engineering, vol. 5, p. 1541, 2018.
[4] G. I. Denny Nathaniel Chandra, I Nyoman Sukajaya, "Klasifikasi Berita Lokal Radar Malang Menggunakan Metode Naive Bayes Dengan Fitur N-Gram," Jurnal Ilmiah Teknologi dan Informasia ASIA (JITIKA), vol. 10, p. 11, 2016.